Red Hat on Development
-
Debugging in GDB: Create custom stack winders
In this article, we will walk through the process of creating a custom stack unwinder for the GNU Project Debugger (GDB) using GDB's Python API. We'll first explore when writing such an unwinder might be necessary, then create a small example application that demonstrates a need for a custom unwinder before finally writing a custom unwinder for our application inside the debugger.
By the end of this tutorial, you'll be able to use our custom stack unwinder to allow GDB to create a full backtrace for our application.
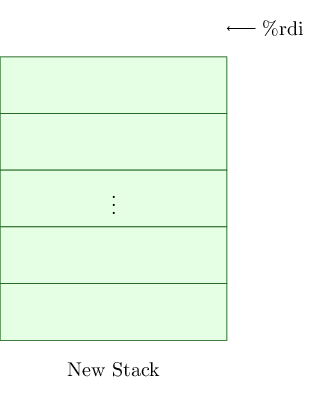
What is an unwinder?
An unwinder is how GDB figures out the call stack of an inferior, for example, GDB's
backtracecommand: [...] -
My advice for designing features for the hybrid cloud
Hybrid clouds are mixed computing environments that allow applications to use a combination of compute, networking, storage, and services in public clouds and private clouds, including clouds running on-premise or at a plethora of edge locations.
To accomplish this, hybrid cloud platforms must be designed to expose the best of the public clouds they support and present the advantages of private clouds while presenting a cohesive interface to the application developer—and preferably the cloud admin, too. A cloud admin can install a cloud instance called a cluster, consisting of a control plane (at least one instance) to manage the cluster and multiple compute instances that run applications on them.
In the rest of this article, "developer" specifically refers to a hybrid cloud platform developer, not an application developer.� As a developer working on OpenShift, Red Hat’s hybrid cloud platform, I have found that designing features around a few key tenets ensures the cohesiveness that hybrid cloud platforms wish to achieve.
-
Fine-tune large language models using OpenShift Data Science
As an Ansible Lightspeed engineer, my team works on the cloud service that interacts with Watson Code Assistant large language models for Ansible task generation. Curious to learn more about the mechanics of training such a model, I set out to create my own, very basic Ansible tasks model. I decided to do this using Red Hat OpenShift Data Science, which made it easy to configure and launch an environment pre-configured with everything I needed to train my model. I’ll walk through the steps I took here.